

To realize 3D spatial sound rendering with a two-channel headphone, one needs head-related transfer functions (HRTFs) tailored for a specific user. However, measurement of HRTFs requires a tedious and expensive procedure. To address this, we propose a fully perceptual-based HRTF fitting method for individual users using machine learning techniques. The user only needs to answer pairwise comparisons of test signals presented by the system during calibration. This reduces the efforts necessary for the user to obtain individualized HRTFs. Technically, we present a novel adaptive variational AutoEncoder with a convolutional neural network. In the training, this AutoEncoder analyzes publicly available HRTFs dataset and identifies factors that depend on the individuality of users in a nonlinear space. In calibration, the AutoEncoder generates high-quality HRTFs fitted to a specific user by blending the factors. We validate the feasibilities of our method through several quantitative experiments and a user study.
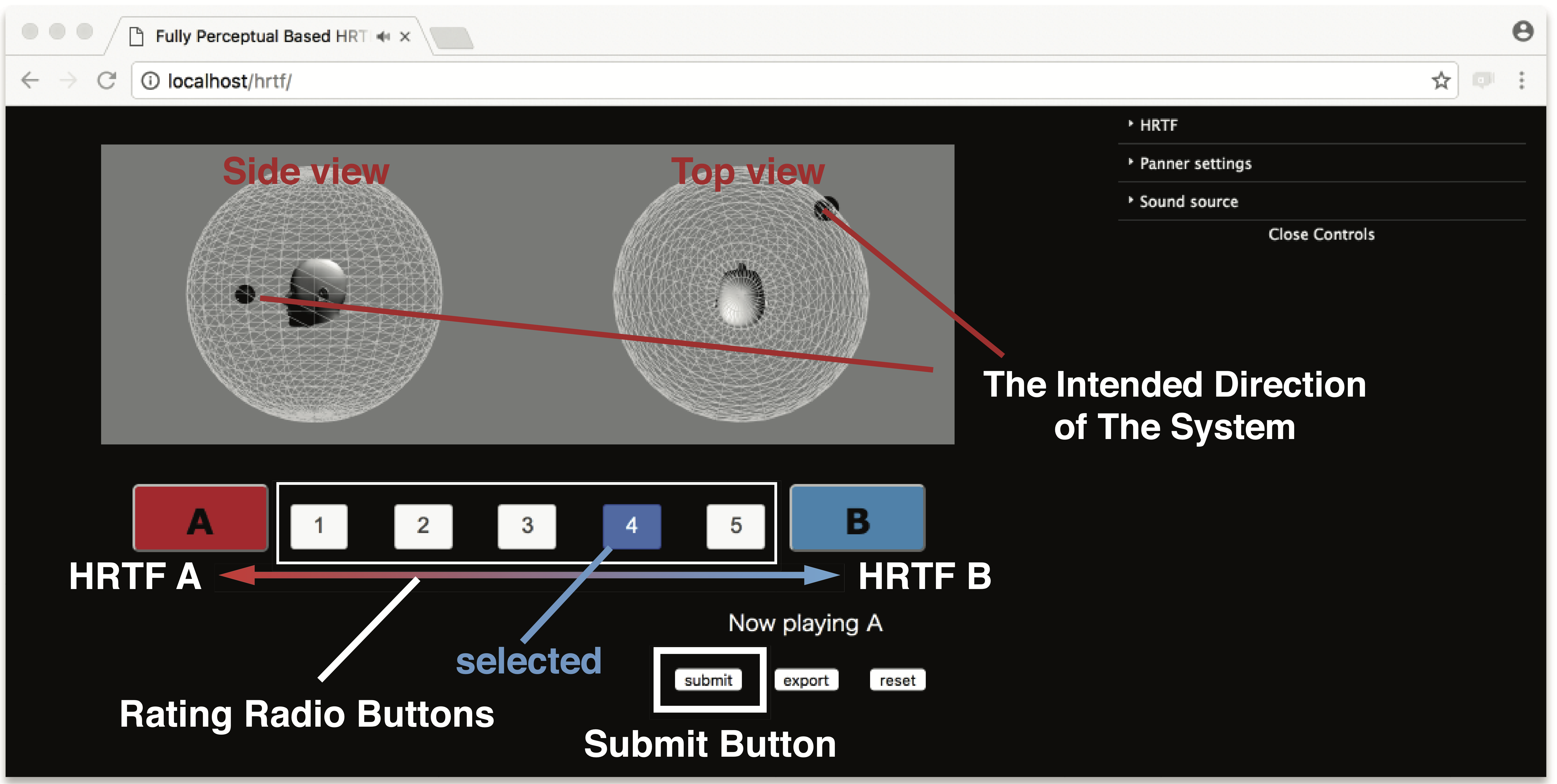
The user can calibrate their own Human Related Transfer Function (HRTF) for 3d audio spatialization. The system presents a pair of test signals, and the user feedbacks which one is perceptually better. Using this feedback task iteratively, our system optimizes a personalization weight for the user to obtain an individualized HRTF. The personalization weight blends individual factors of HRTF which are extracted from a public HRTF data set during training. After calibration, our system outputs the individualized HRTF in an arbitrary required format for each rendering platform.
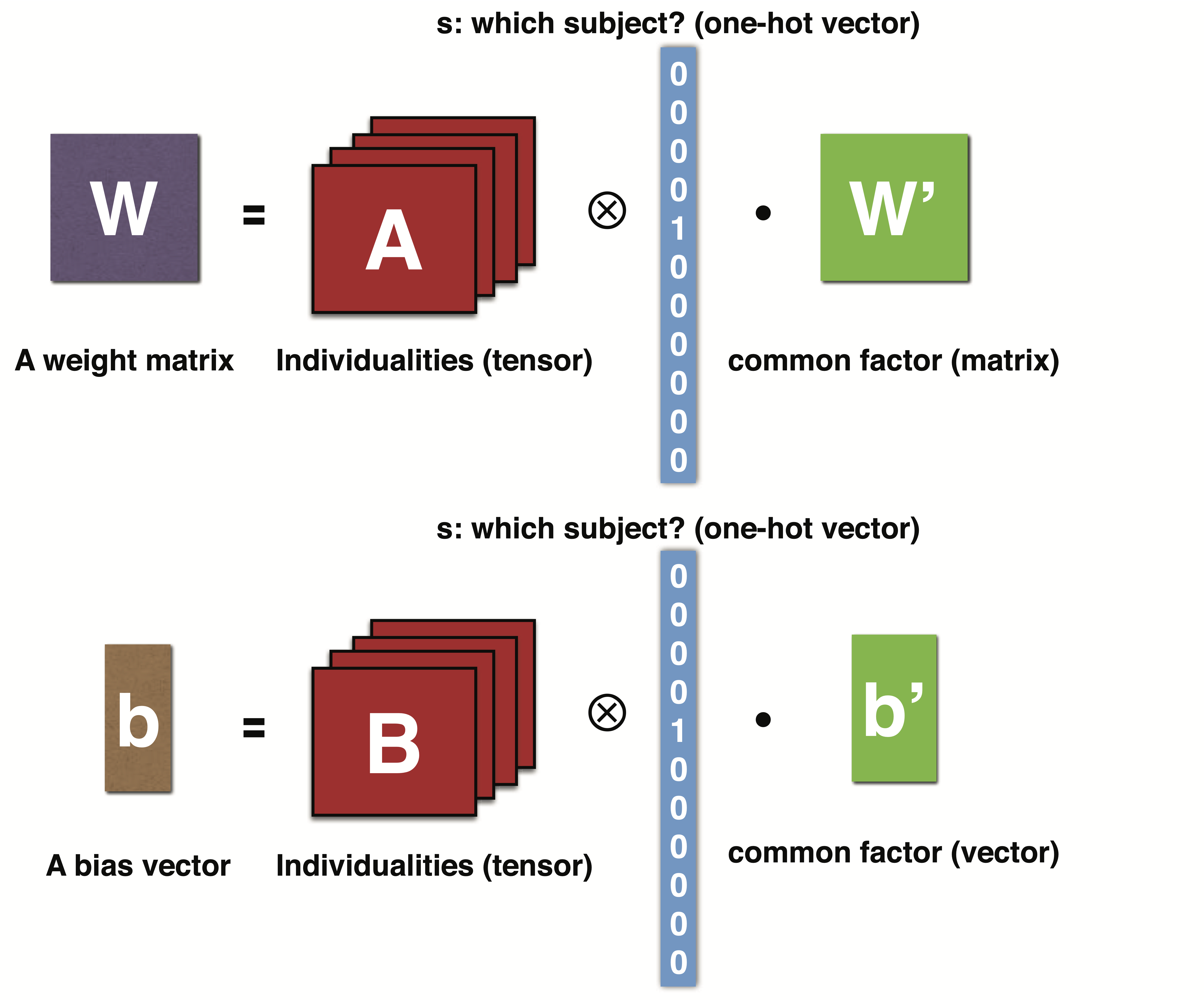
Our primary technical contribution is decomposing the individual and non-individual factors from an HRTF dataset during training. This technique uses a novel type of neural network layer called an adaptive layer, which isolates the latent individualities into a tensor from the weight matrix in an unsupervised manner. In addition to the input vector, this adaptive layer uses a one-hot vector during training and a continuous blending vector during runtime as input. This adaptive layer allows us to interpolate, emphasize, diminish, and blend each individuality in the trained dataset by adjusting the personalization weight vector at runtime.
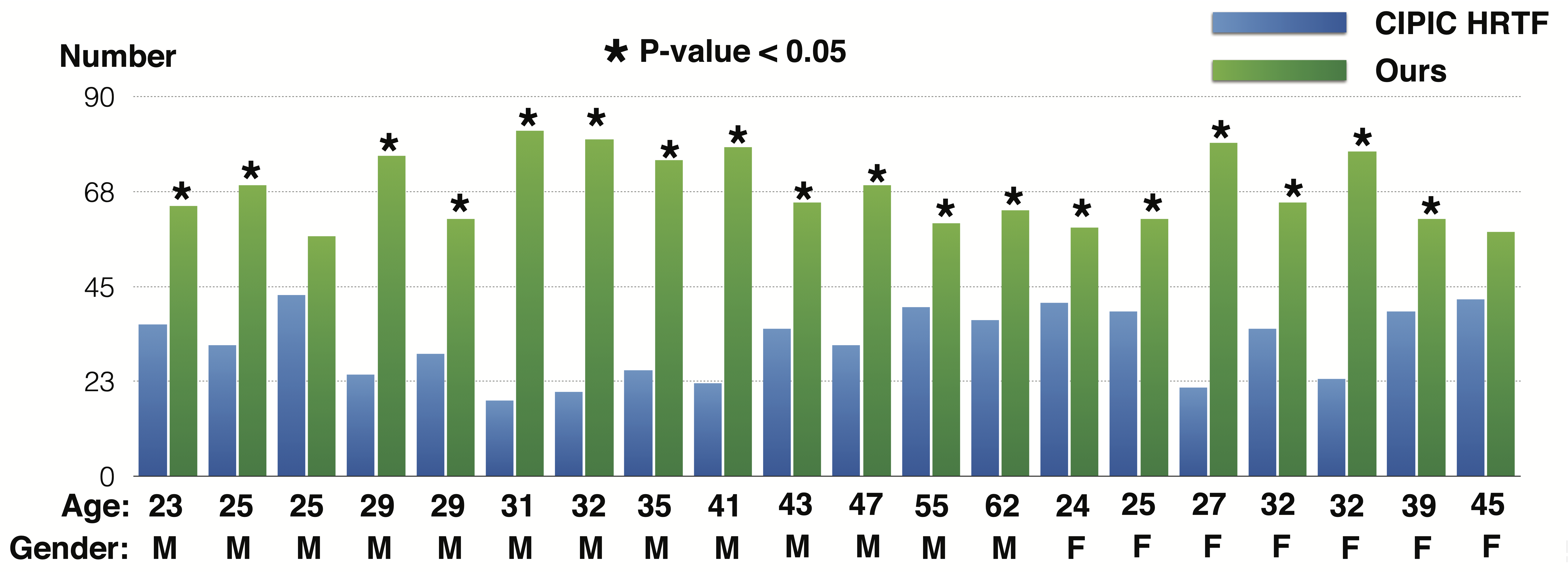
The result of user study. The third column shows how many num- bers of options are selected as better HRTF for each participant between best fitted CIPIC HRTF and optimized HRTF by our system. This shows that the optimized HRTFs were significantly better for almost all participants than were the best CIPIC HRTFs, indicating that our system successfully optimizes HRTFs for individual users.

・Kazuhiko Yamamoto, and Takeo Igarashi. 2017. Fully Perceptual-Based 3D Spatial Sound Individualization with an Adaptive Variational AutoEncoder.
ACM Transaction on Graphics (SIGGRAPH Asia), 2017, 36, 6, pp.212:1-212:13 [PDF]
・山本 和彦, 五十嵐 健夫. 2017. Adaptive Variational AutoEncoderによる3次元音響の特定個人への知覚ベースキャリブレーション.
WISS, インタラクティブシステムとソフトウェアに関するワークショップ, 2017 [PDF]
@article{10.1145/3130800.3130838,
author = {Yamamoto, Kazuhiko and Igarashi, Takeo},
title = {Fully Perceptual-Based 3D Spatial Sound Individualization with an Adaptive Variational Autoencoder},
year = {2017},
publisher = {ACM},
volume = {36},
number = {6},
url = {https://doi.org/10.1145/3130800.3130838},
doi = {10.1145/3130800.3130838},
journal = {ACM Transactions on Graphics (TOG)}
}
Kazuhiko Yamamoto – www.yamo-n.org
mail: yamo_o(at)acm.org
twitter: @yamo_o

